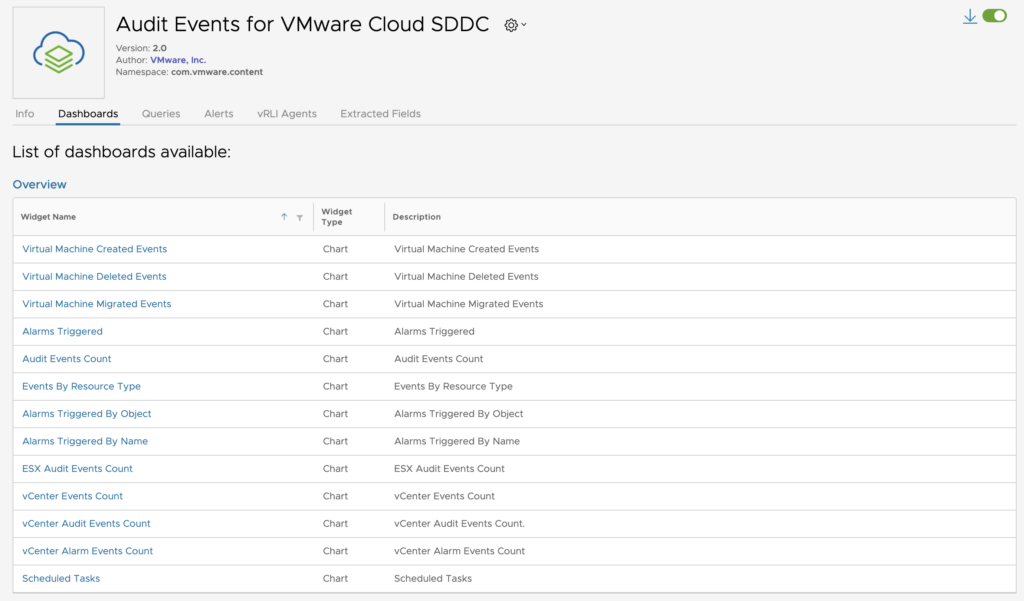
Today I wanted to cover a topic that was recently raised by one of my customer about how to filter routes coming from a native TGW attached to an SDDC with a Route Based VPN.
There are currently no way to do it over the UI but it is possible through an API call to configure route filtering in and out with a Route Based VPN.
Let’s see how it is possible.
Route Based VPN attachment to a native Transit Gateway
First thing I have created a route based VPN from my SDDC to a native Transit Gateway running on AWS.

The Transit Gateway is itself attach to a native VPC with 172.16.0.0/16 as subnet.
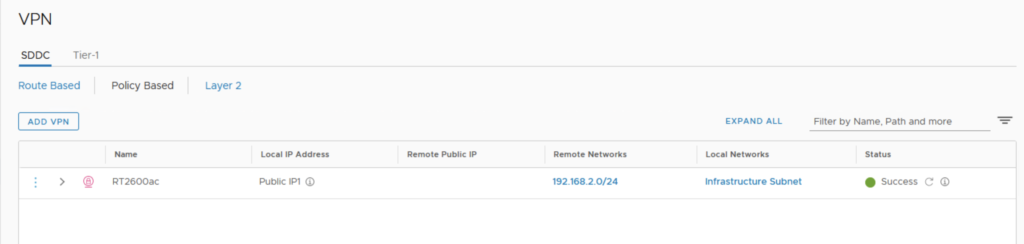
Let’s have a look at the VPN configuration in the SDDC and in the native AWS side.
AWS Transit Gateway VPN configuration
There is a site to site VPN configured with one tunnel (I didn’t configure two tunnels in that example).

The TGW is currently learning the SDDC subnets (see the 5 BGP ROUTES) including the management segment.

In order to see all the learned CIDRs, I need to display the Transit Gateway route table.

SDDC VPN configuration
If we look at the VPN configuration on the SDDC side, here is the result.

And if I click the View routes here

I can see the learned routes …

and the Advertised routes.

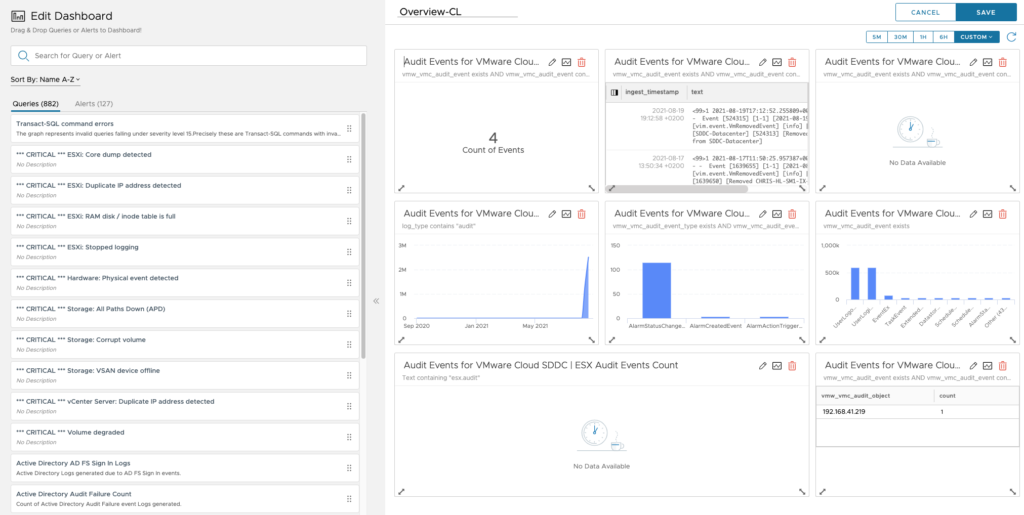
I can confirm that by default everything is learned and advertised.
Let’s see how to limit the propagation of the routes from the TGW or the SDDC through an API call.
Installing and Configuring Postman
Download Postman
First I have downloaded Postman from here and installed it on my Mac laptop.
First thing you need to do when you have installed Postman is to create a new free account.

Click Create Free Account and follow the steps until finishing your free registration.
This will bring you to the following page with a default Workspace.

Import VMC on AWS Collections
Next thing you need to do is to import the VMC on AWS Collections and Environments variables that are directly available from VMware in the vSphere Automation SDK for REST. The VMware vSphere Automation SDK for REST provides a client SDK that contains samples that demonstrate how to use the vSphere Automation REST API and sample code for VMC on AWS and others.
Click on the download button of the Downloads section.

This will download a zip file that you need to extract.
This is going to redirect you to a Github repo. Just click on the green button called “Code” and pick Download.

Once you have downloaded, select the two following files: VMC Environment.postman_collection.jsonandVMware Cloud on AWS APIs.postman_collection.json and Import both into your Postman workspace.


This will add the collection with different sub folders.

Configuring VMC on AWS environments in Postman
If you click on the Environments section on the Left, you can setup multiple environment variables here including the SDDC ID, ORG ID and a refresh token.
Start by generating an API token, grab the information of SDDC from CSP Console and copy them in the CURRENT VALUE column.

Add the following variables with the following values:

Configuring the VMC APIs Authentication
Once you have downloaded the VMC on AWS APIs collection, we need to configure a few parameters here.
Select the Authorization tab, and change the Type from No Auth to API Key.

Change the Value to {{access_token}}, “Add to” has to be kept as Header.

Limiting routes through API calls with Postman
Create a new Collection for NSX API Calls
Here we are going to import an existing collection that has been created by my colleague Patrick Kremer here on Github. By the way Patrick has also an excellent post here and even if it’s not covering the exact same use case it was a lot inspirational to me. I would like also to mention another excellent content from Gilles Chekroun.
Follow the same steps as before for the VMC collections this will add the following:

The two first are useful to check the configuration and the two others are used to implement things
Authenticating to VMC API
Now we can Login to the VMC on AWS API in order to execute the relevant command to create the Prefix Lists and do the Route filtering.
In order to do so, Select Login in the Authentication folder and Click the Send button on the right.

The body of the request shows a new access token which is valid for 1799 seconds.

Creating a Prefix List
Now we need to create a prefix list in order to limit SDDC subnets to be advertised to the Transit Gateway through the BGP session of the route based VPN. Let’s say we want to limit the management subnet 10.73.118.0/23 to be accessible from the VPC. We also want to avoid that we can access the VPC (172.16.0.0/16) from the SDDC.
In order to achieve that we need to create two prefix lists, one to filter in and one to filter out.
From the Postman select Create Prefix List, give the prefix list ID a value.

I have chosen filter_mngt_subnet for the first Prefix List ID.
Next is to the body of the request.
{ "description": "This will filter the Management subnet from SDDC", "display_name": "{Filter out Management subnet}", "id": "{{prefix-list-id}}", "prefixes": [ { "action": "DENY", "network": "10.73.118.0/23" }, { "action": "PERMIT", "network": "ANY" } ]}

Just click Send to add the Prefix List.

The result of the creation is a 200 OK.
I have created a second Prefix List in order to limit the VPC subnet from being advertised to the SDDC.


Display the Prefix Lists
Next step is to check the Prefix Lists has been created successfully by leveraging the Show BGP Prefix List command.

You should see the Prefix lists with all the already created ones.

Attaching the Prefix List to the route Filter
Now we have to attach the Prefix Lists to the BGP Neighbors configuration.
First of all grab the existing configuration by using the Show VMC T0 BGP Neighbors GET command.

The result is displayed as follow.

Copy this text and remove the following lines: _create_time, _create_user, _last_modified_time, _last_modified_user, _system_owned, _protection, _revision.
Now we are going to append the prefix Lists to the configuration by using the latest command: Attach Route Filter.
Grab the Neighbor ID from the result and paste it to the VALUE.

Copy and paste the previous result into the Body of the command and the prefix list command in an out.

Click the Send button.
Checking routes Filtering
If I check on the SDDC side I can see that the management subnet is now filtered out.

I confirmed it by checking on the AWS side in the Transit Gateway route table.

To conclude, I can also confirm that the VPC subnet is not advertised in the SDDC as I don’t see it as a learned route.

That concludes my post, enjoy filter out the routes!