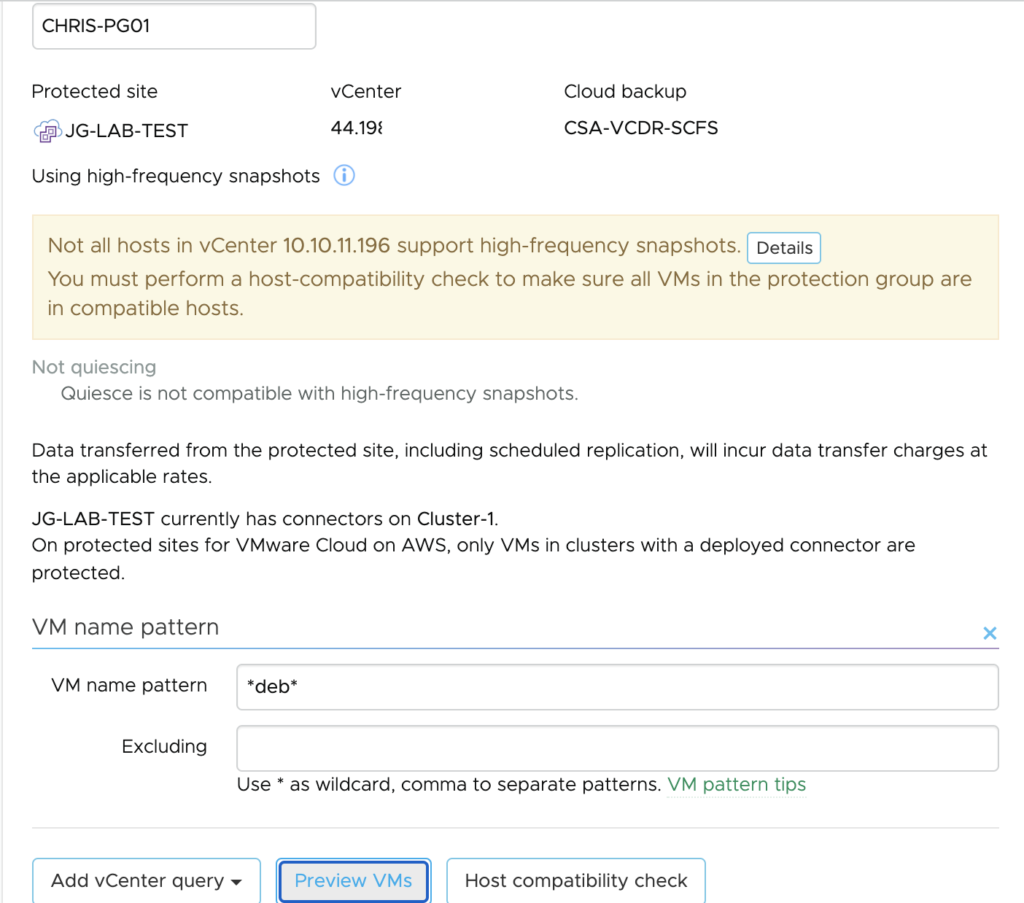
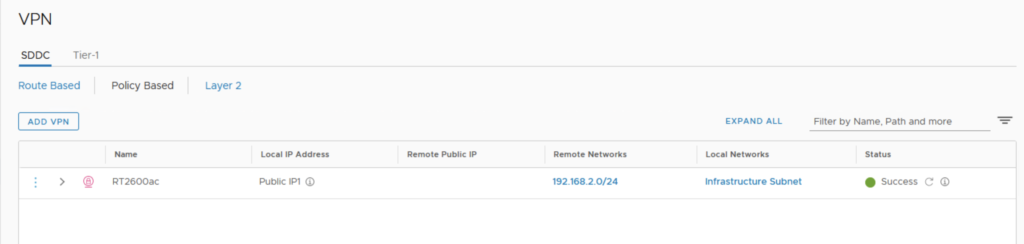
In the previous post I have showed you how to create Protection Groups for my VMs. It’s now time to create the DR strategy and run a Test Failover and real Failover.
Planning the DR strategy
The DR strategy is enforced through the concept of DR Plan where we are going to help plan the different parameters that sustains the strategy including defining the protected resources, the orchestration order of the recovery process, and several additional options when the failover executes like changing the IP adresses or executes scripts.
Create a DR Plan
A DR plan defines the orchestration configuration for implementing the disaster recovery Strategy.
The following operations are allowed under the DR plan section:
- Configuring DR Plans – require defining where you want your protected data moved to when the plan runs.
- Viewing DR Plans – shows the currently defined plans along with plan summary information: the current status, protected and recovery sites, and the last run compliance check results.
- Activating DR Plans – can be in an active or deactivated state.
In order to create a DR Plan, I need to click on Create plan from the DR plans Menu.

Just give it a name and choose between using an existing recovery SDDC (Pilot Light) or make the SDDC deployed when a DR occurs.

In the next step, I have to select the source SDDC that is going to be my Protected site in this scenario.

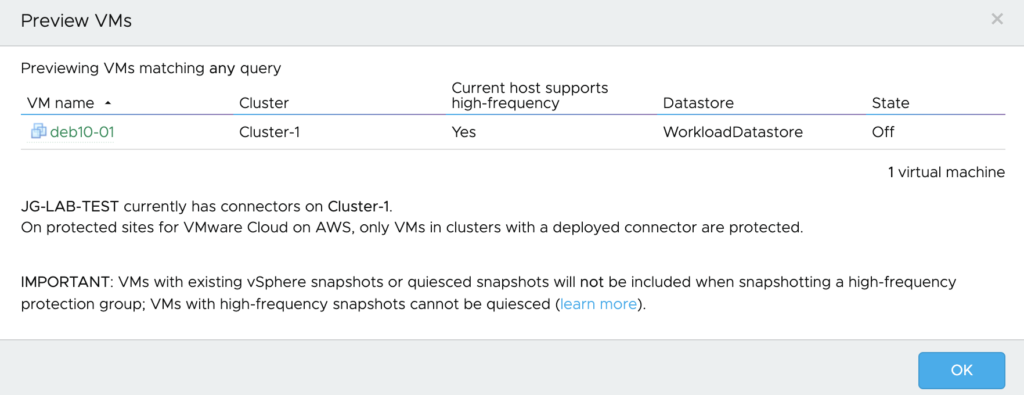
I chose the Protection group I defined earlier.

Next steps are to map the different resources (datastores, folders, resource pools, virtual networks…) from the Protected to Recovery site.
It’s very important to map differences between the sites for smooth recovery, ensuring that vSphere configurations and parameters are mapped consistently between sites.
For folder, I have mapped my Workloads folders on both sites.

I kept the same mapping for the Resource pools and picked Compute-ResourcePool as this is where workloads are running in a SDDC.

For the segments, I have mapped the source segment to a different subnet in the recovery SDDC.

Keep in mind that Test and failover mappings can be different by unselecting the Same for test and failover button. Maybe you want to use a different subnet for testing (for instance an isolated one).

Next thing is the IP address mapping rules that’s helping to change the range of IPs, subnet masks and DNS settings at failover time. It does that by interacting with the VMTools in the VM while it’s running.

Next thing is the ability to execute a script of any language for both Windows and Linux machine types from a script host. The script can be executed at a specified time from this script VM. The script VM need to be running in the Recovery SDDC and available from the vCenter of the recovery SDDC . You will call the script from the VM with any parameters you want to be running during the failover sequence.

To finish, the Recovery Steps will specify the order in which you want your VMs to be recovered.
There are different options under the Recovery Steps.
- Choose a step which can be executed for either whole protection groups or an individual VM under the protection group.
- Select the Power action for recovered VMs.
- Select Pre-recover or Post-recover actions from the drop-down menu which can be running scripts which were saved under step 4 above.

For exemple, I chose to recover one VM first (could be a DB for instance), add a delay of 30 seconds, recover the remaining VMs (could be the remaining App VMs) and ask for a validation.

Lastly after you build the plan you can configure alerting.

Please note that vCDR uses the AWS mail service to send alerts. Recipients must respond to an email address verification Request before getting email from vCDR.
I did receive that email:

The validation occurred after I clicked on the link above:

Now it’s time to test the Plan and execute a failover.
Validating compliance of a DR Plan
In order to make sure the failover going to work, vCDR is performing a couple of compliance check. Continuous compliance checks verify the integrity of a DR plan and ensure that any changes in the failover environment do not invalidate a DR Plan’s directives when running.

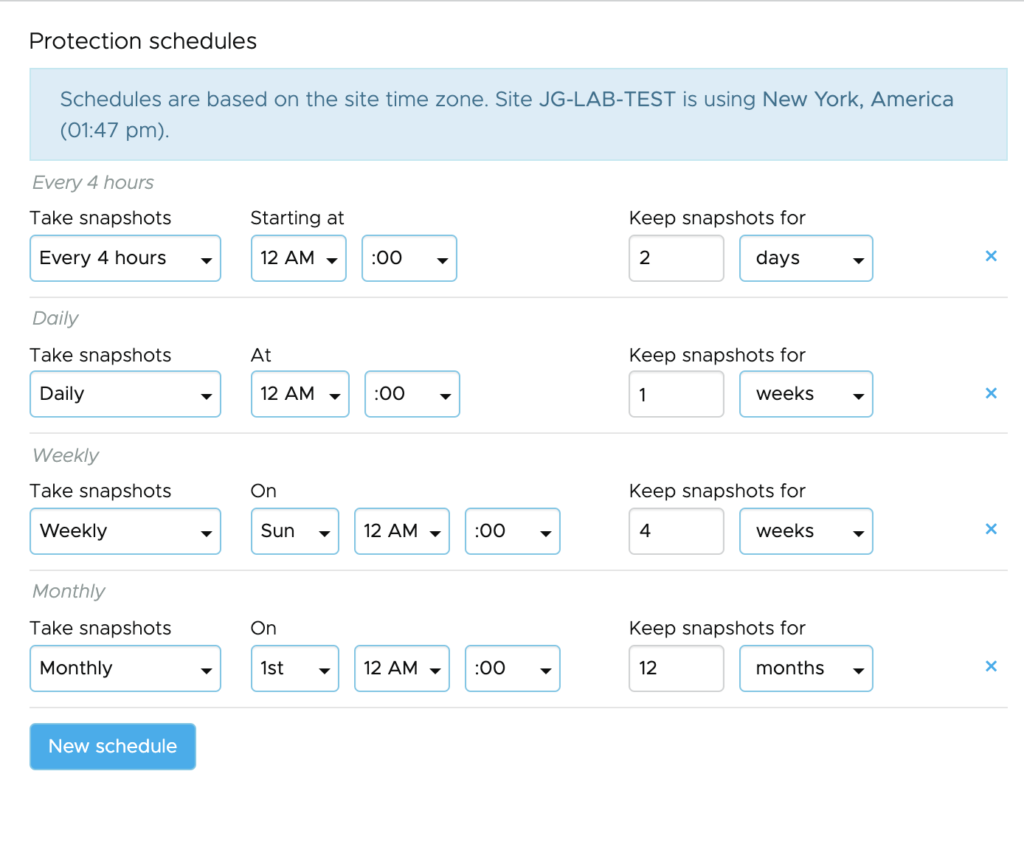
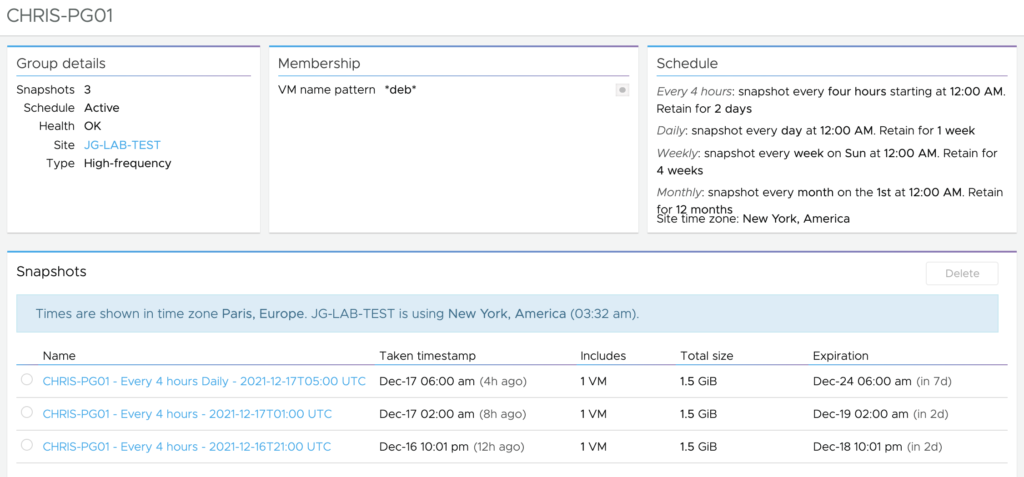
Once a DR Plan is completed, the ongoing compliance checks runs every half an hour. It’s checking all the steps in the DR plan including the mappings, the source and destination environment availability and it keeps tracks of the mappings.

As I have opted in for it, at the end of the compliance check, I have received a Report by email with all the results of the checks.
The report shows a folder mapping that wasn’t including the VMs in my Protection Group so I did add the root folder in the mapping.

I forced a new compliance check by clicking the right arrows button.

There were still an error related to the proxy agent VM that vCDR automatically deployed in the SDDC.

Indeed there is a Cloud PRXY DR VM that have been created on my recovery SDDC as you can see.

This proxy VM is attached to a newly deployed network.

The created network is dedicated to the cloud DR proxy VM and it has the following subnet: 10.68.97.0/26.

Executing a Test
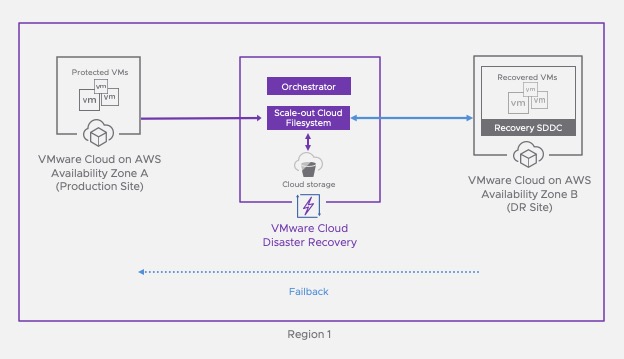
Every plan has the option to do a Test Failover or an actual Failover. The difference between a Failover and a Test is that a fail back will be required post a Failover where in a test you are just bringing a copy of your VM in the cloud and a fail back is not needed because you don’t want to overwrite the existing VMs on premise.
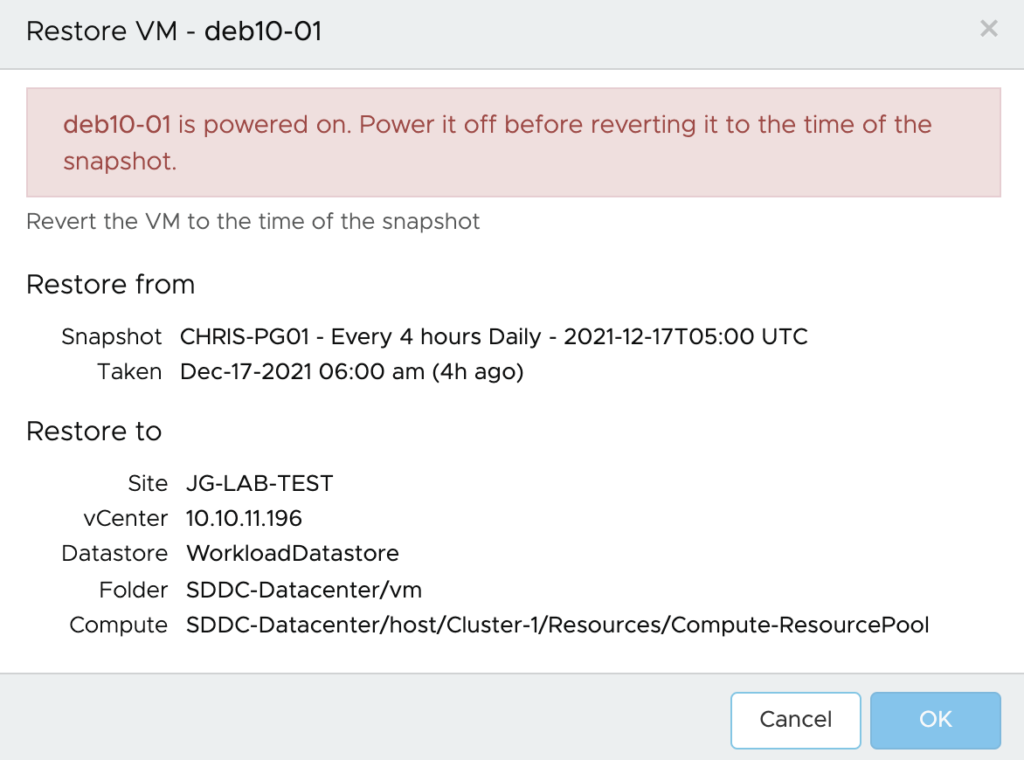
A failover means the production is down, so during a failover you actually take the VM to DR Site up and running. During a failover you will be ask which recovery point you want to pick.
A test failover runs in the context of its own test failover environment, specified by the DR plan’s test mapping rules. The results of the test failover do not permanently affect a target failover destination.
In order to test my plan, I just clicked on Test from the DR Plan menu.

The DR Test ask for which recovery Point within your catalog you want to pick.

You cab select any one of them in the entire protection Group. We can go back to any recovery point.


I have followed the wizard and first selected Ignore all errors.

With the Test, I had the option to run the VMs directly from the cloud backup which is the Cloud Filesytem sitting on top of S3 or to do a Full storage migration to the Recovery SDDC. The latest one means just after the VMs will be registered in the Cloud, they will be “storage vMotioned” from the SCFS into the vSAN Datastore of the SDDC. Obviously running the VM from the Cloud backup will not be as fast as all flash vSAN.
I kept Leave VMs and files in cloud backup for this test.
I confirmed that I wanted to kick off the test by writing TEST PLAN and clicked Run test.

After the test started, it has populated the VM in the Recovery SDDC.
So I have launched the Recovery SDDC vCenter from vCDR portal and could copy the credential as they are captured in it (very handy!).

I could see the my Two VMs in the Protection Group have been restored.

Once the test is over, you have to clean up the test by undoing the tasks, unregistering the VMs and revert back to initial state.

The clean up process is deleting the VMs from the SCFS as you can see.

The two VMs get unregistered from my vCenter.

Everything that have been done during my failover test is documented and is available through a pdf report where every steps is detailed.
I have generated it from the DR Plan Menu.

The Pdf report was autogenerated and downloaded in my local folder.


The report has multiple pages and is quite detailed as it includes the results of my test, the workflow steps, mappings and the time that it took per VM to come up, …

This is a great document to share with compliance people inside the organization.
That concludes my latest post of the year. Enjoy en of Year Celebration and see you next Year!