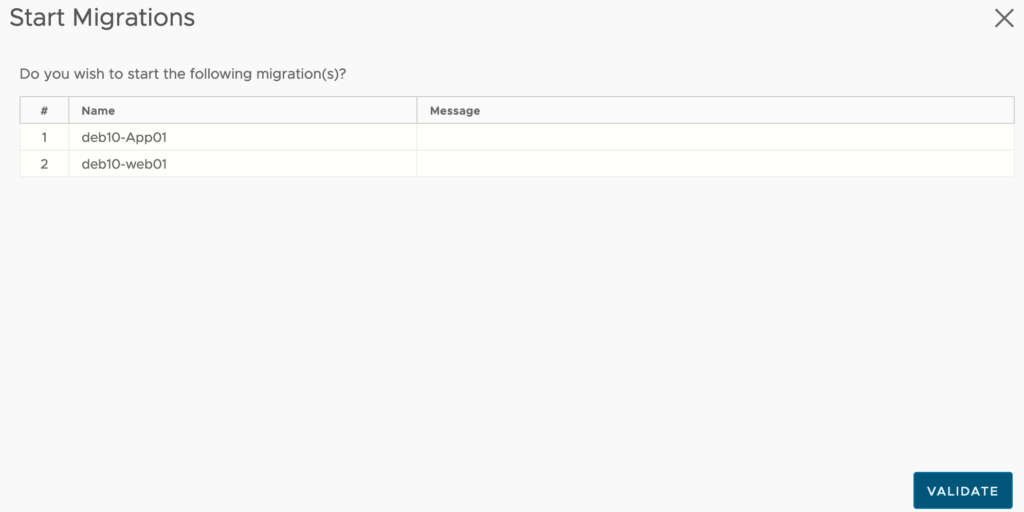
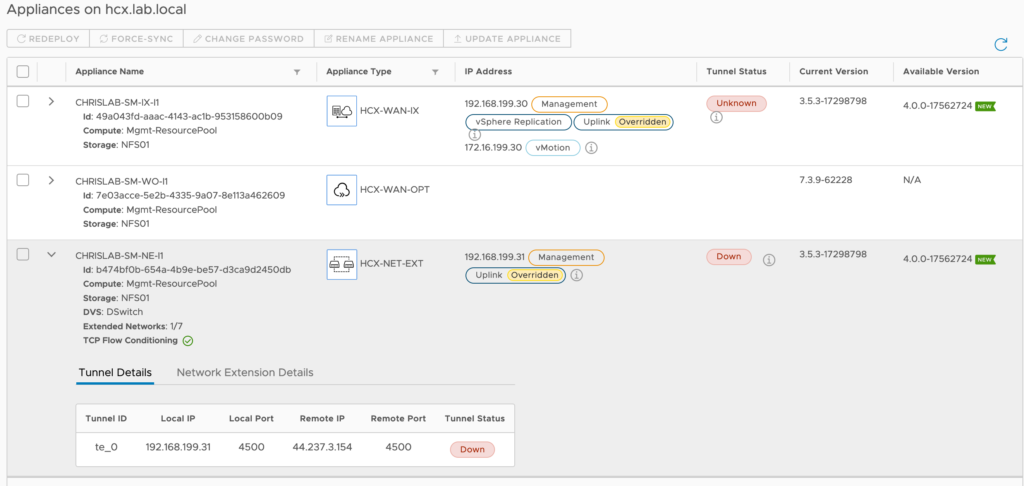
I recently have had a question from a customer asking me how the default route is managed into HCX when Mobility Optimized Network is enabled.
Basically when extending multiple VLANS from on-premise to VMware Cloud on AWS by leveraging HCX, you may still want to send egress traffic to an on-premise security device in order for the workloads running in the SDDC to be protected.
I decided to check the way HCX is managing default gateway in my own on-premise lab.
Testing the default gateway with MON
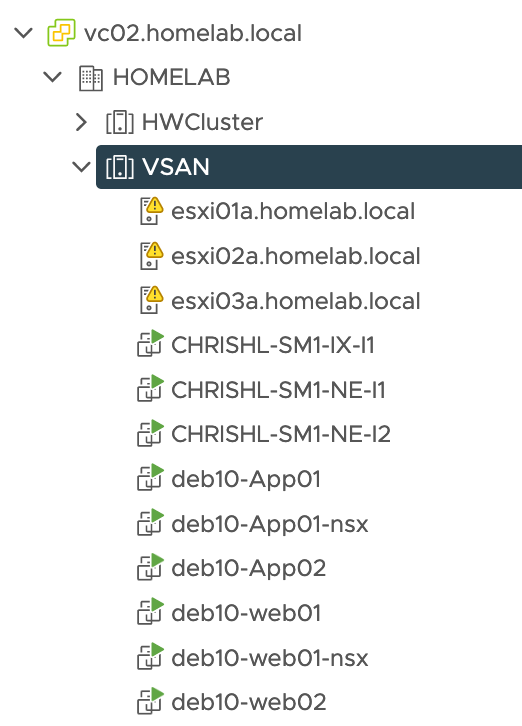
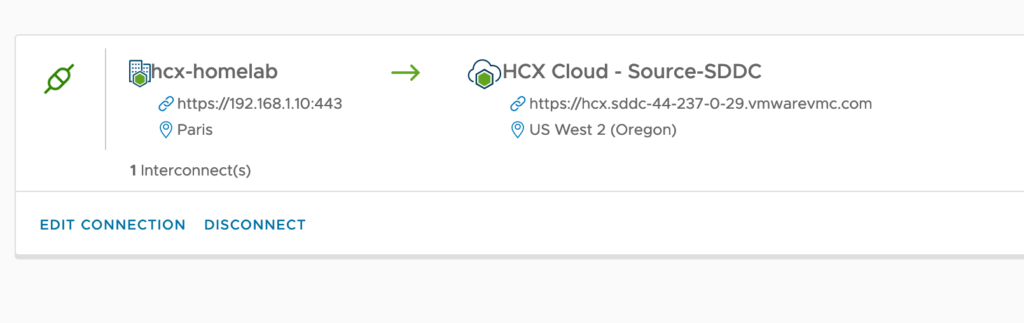
I have a VMware vSphere lab environment with a 3 nodes VSAN cluster which is link via Internet to an SDDC that I have deployed with Terraform on our internal CSA Organisation. I have already established site pairing between both sites:

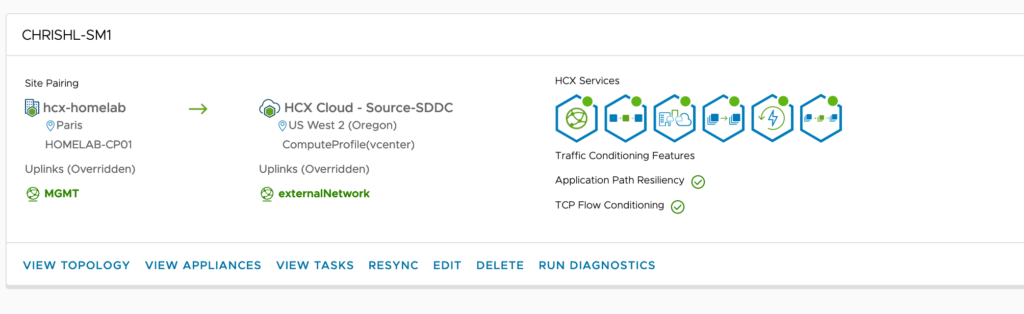
And created a service mesh:

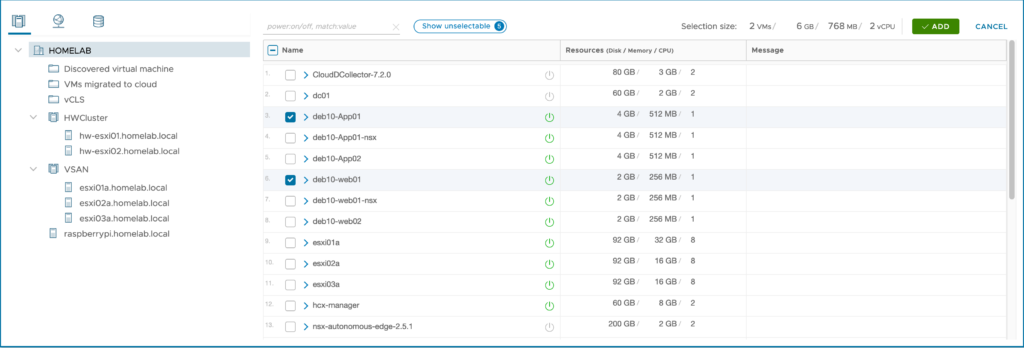
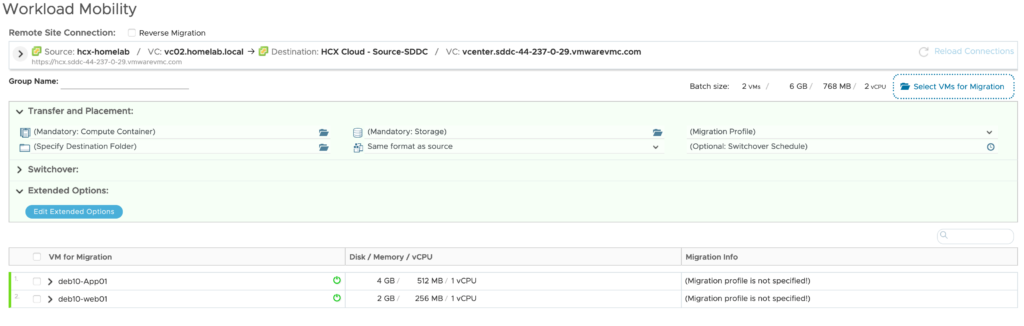
Then I have extended 3 networks to the VMware Cloud on AWS SDDC: APP (VLAN 1712), DB (VLAN 1713) and WEB (VLAN 1711).

On the APP network (VLAN 1712), I have deployed one VM (DEB10-APP01) which is running in my VSAN on-premise 3 nodes cluster. This network Extension hasn’t MON feature enabled.

I have also setup a second subnet called WEB(VLAN 1711). I have another VM (DEB10-WEB01) running there, which have been migrated on a new cluster in VMware Cloud on AWS. This extended network is MON enabled.

I have open a shell session and try to ping the on premise VM DEB10-APP01 from DEB10-WEB01. The trafic is flowing over the internet to my on-premise site through the service mesh:

Now I wanted to check where the default route is in the SDDC. Is it going to be the IGW through the T0 router or is it going to be the on-premise gateway?
To check, I have traceroute to the 8.8.8.8.

This is not using my on-premise gateway to egress traffic. However default traffic is going out through the T0 router and internet gateway of the SDDC in AWS.
So now how can I make traffic on a MON enabled network to egress via on-premises?
How the HCX MON Policy routing works?
How HCX MON Policy routing works is very simple. When MON is enabled on a network extended segment, HCX adds the gateway IP with /32 net mask into the SDDC Compute Gateway. For each VM that has MON enabled there is also a /32 route injection for created or Migrated Virtual Machines. So whenever a Virtual machine on the different segment in the SDDC wants to reach the VM it will allow reachability from SDDC Compute Gateway.
There is a default setting in the Policy routing that is evaluated whenever a destination is not within the SDDC:
If the destination IP is matched in the policy and allowed by the policy, the trafic is forwarded to the on-premise gateway. If the destination IP is not listed in the policy settings then the traffic is sent to the T0 router in the SDDC and routed accordingly.
Changing the HCX MON Policy routes
This setting can however be changed by editing it through a menu available from the ADVANCED tab in the console:

The default MON Policy setting is, as displayed, allowing only RFC-1918 subnets to be routed back to on-premise gateway :

To change the default policy routing to route default egress traffic to on-premise, you simply have to add a 0.0.0.0/0 route in the list as allowed.

The default route is now displayed in the policy Routes setting:

Default route means that Internet traffic will flow over the Interconnect from SDDC to the on-premise gateway.
Let’s check it by launching a traceroute again from my VM in the SDDC:

It shows now that the traffic is sent to my on-premise default gateway (192.168.2.1).
Conclusion
When you have MON enabled with the default route policy settings and you are advertising 0.0.0.0/0 into the SDDC, HCX ignore this and still send traffic out of the IGW.
Whenever you advertised the default route to the SDDC through BGP, you must change the default Policy to avoid egress traffic to be sent to the Tier-0 router, otherwise you will experience asymmetric routing.